Content
Introduction to Local Co-Location Quotient (LCLQ)
Basic Principles
Application of LCLQ
Mathematics of LCLQ
Interpretation of LCLQ
21 Feb 2023
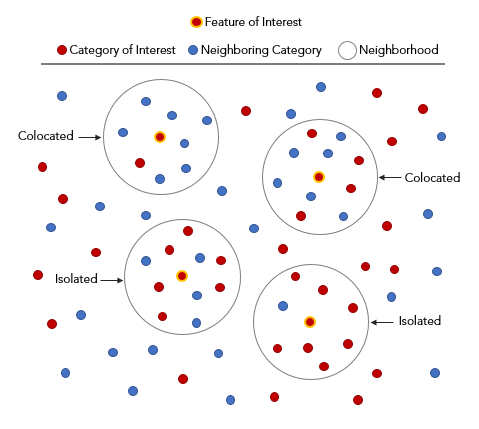
A point event category A is colocated with point events of category B if it is surrounded by several point event category B within a specified distance.
Each feature in the Category of Interest (category A) is evaluated individually for colocation with the presence of the Neighboring Category (category B) found within its neighborhood. In general, if the proportion of B points within the neighborhood of A is more than the global proportion of B, the colocation quotient will be high. If the neighborhood of A contains many other A points or many other categories other than B, the colocation between the Category of Interest (category A) and the Neighboring Category (category B) will be small.
The local colocation quotient calculated from point Ai in the Category of Interest A to the Neighboring Category B is given as:
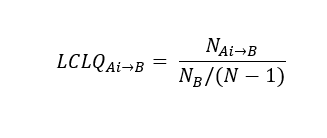
Where NB is the total number of category B present in the study area, and N is the total number of points in the study area (including all categories present). NAi–>B is the weighted average of the number of category B points in the neighborhood of each category A point (Ai). This is based on a distance decay function that allows closer features to the target feature to weigh heavier in the calculations than features that are farther away.
NAi–>B represents the weighted average of the number of type B points in the neighborhood of each Ai based on either a Gaussian or Bisquare kernel function given as:
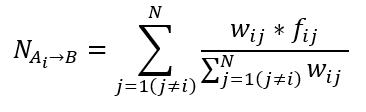
Where fij is a binary variable indicating whether point j is a category B point. If this is true, it is equal to 1. If not, it is equal to 0. The kernel function equations are given as:
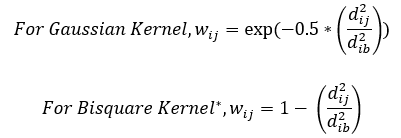
Note
If the value of wij is negative for the Bisquare kernel, the weight assigned is 0.